やったこと
ブラウザの仕組み: 最新ウェブブラウザの内部構造
こいつを読んだ!
1. 初めに
ブラウザの主な機能
ブラウザの主な機能はユーザーの選択したウェブ リソースをサーバーに要求してブラウザ ウィンドウに表示することにより、ユーザーに提示することです。
不思議なことに、ブラウザのユーザー インターフェースは正式な仕様では規定されていません。長年の経験から優れた実践手法が形成され、互いに真似し合うことによって生まれたものです。
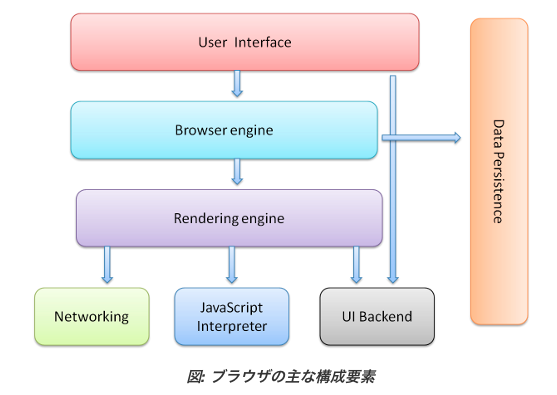
ブラウザの上位構造
- ユーザー インターフェース
- アドレスバー、戻る/進むボタン、ブックマーク メニューなどがあります。
- ブラウザ画面のうち、要求したページが表示されるメイン ウィンドウを除くすべての部分です。
- ブラウザ エンジン
- UI とレンダリング エンジンの間の処理を整理します。
- レンダリング エンジン
- 要求されたコンテンツの表示を担当します。
- たとえば、要求されたコンテンツが HTML の場合は、HTML と CSS を解析し、解析されたコンテンツを画面に表示します。
- ネットワーキング
- HTTP リクエストなどのネットワークの呼び出しに使用されます。
- プラットフォームに依存しないインターフェースと、プラットフォームごとの下部の実装を備えています。
- UI バックエンド
- コンボ ボックスやウィンドウなどの基本的なウィジェットの描画に使用されます。
- プラットフォームに依存しない汎用的なインターフェースを公開し、その下ではオペレーティング システムのユーザー インターフェース メソッドを使用しています。
- JavaScript インタープリタ
- JavaScript コードの解析と実行に使用されます。
- データ ストレージ
- 永続的なレイヤです。
- ブラウザでは Cookie などさまざまなデータをハード ディスクに保存する必要があります。
- 新しい HTML 仕様(HTML5)では、ブラウザ内の完全で軽量なデータベースである「ウェブ データベース」が定義されています。
#### レンダリング エンジン
レンダリング エンジンの仕事は「レンダリング」、つまり、要求されたコンテンツをブラウザの画面に表示することです。
参考ブラウザの Firefox、Chrome、Safari は 2 つのレンダリング エンジン上に構築されています。
Safari と Chrome では Webkit を使用しています。
レンダリング エンジンはまず、要求したドキュメントのコンテンツをネットワーキング レイヤから取得します。この処理は 8 キロバイト単位で行われます。
レンダリング エンジンのその後の基本的なフローは次のとおりです。

- レンダリング エンジンは HTML ドキュメントの解析を開始し、タグを「コンテンツ ツリー」というツリー内の DOM ノードに変換します。
外部の CSS ファイルと style 要素内のスタイル データを解析します。スタイル情報と HTML 内の視覚的な指示を組み合わせて、「レンダー ツリー」という別のツリーが作成されます。 - レンダー ツリーが構築されると、「レイアウト」処理に進みます。
つまり、画面に表示される正確な座標が各ノードに割り当てられます。 - 次の段階は「描画」です。
レンダー ツリーが走査され、UI バックエンド レイヤを使用して各ノードが描画されます。
解析
解析はレンダリング エンジンの中で非常に重要な処理
ドキュメントの解析とは、ドキュメントを意味のある構造(コード内で解釈し、使用できる形式)に変換することです。
例 -「2 + 3 - 1」という式を解析すると、次のようなツリーが返されます。
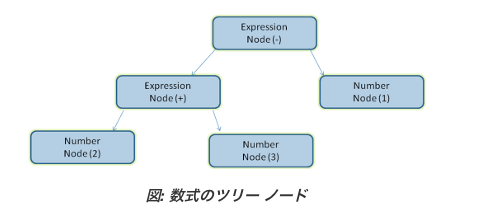
パーサーとレキサーの連携
解析は「字句解析」と「構文解析」の 2 つのサブプロセスに分けることができます。
字句解析は、入力をトークンに分割する処理です。トークンは言語の語彙(有効な構成要素の集まり)に相当します。
構文解析は、言語の構文ルールを適用することです。
通常、パーサーでは処理を 2 つの構成要素に分けて行います。入力を有効なトークンに分割する「レキサー」(または「トークナイザー」)と、言語の構文ルールに従ってドキュメントの構造を分析し、解析ツリーを構築する「パーサー」です。
パーサーの種類
パーサーには、「トップダウン パーサー」と「ボトムアップ パーサー」という 2 つの基本的な種類があります。
- トップダウン パーサーは構文の上位構造を調べて、いずれかの構文ルールと一致させようとします。
- ボトムアップ パーサーはまず入力を調べて、段階的に構文ルールに変換していきます。
解析アルゴリズム
HTML は通常のトップダウン パーサーやボトムアップ パーサーでは解析できません。
その理由は次のとおりです。
- 言語の寛容な性質。
- 無効な HTML のよく知られたケースに対応するため、ブラウザでこれまでエラーが許容されてきたこと。
- 解析処理が「再入可能(リエントラント)」であること。通常は解析中にソースが変更されることはありませんが、HTML では、「document.write」を含むスクリプト タグによってさらにトークンが追加される場合があるため、実際には解析処理中に入力が変更されます。
アルゴリズムは「トークン化」と「ツリー構築」の 2 段階で構成されています。
トークン化は字句解析であり、入力を解析してトークンに分割します。HTML トークンには、開始タグ、終了タグ、属性名、属性値などがあります。
トークナイザーはトークンを識別し、ツリー コンストラクタに渡すと、次のトークンを識別するために次の文字を処理します。これを入力の最後まで続けます。

トークン化アルゴリズム
このアルゴリズムの出力は HTML トークンです。アルゴリズムはステート マシン(状態マシン)として表現されます。
したの例をトークン化してみる
<html>
<body>
Hello world
</body>
</html>
- 最初の状態は「データ状態」です。
<文字に遭遇すると、状態は「タグ開始状態」に変わります。 - a-z 文字を読み込むと「開始タグ トークン」の作成が始まり、状態は「タグ名状態」に変わります。
>タグに達すると、現在のトークンが出力され、状態は再び「データ状態」に変わります。- 次の入力
/を読み込むと「終了タグトークン」の作成が始まり、「タグ名状態」に移ります。 - 再び、> に達するまでこの状態に留まります。新しいタグ トークンが出力されると「データ状態」に戻ります。
ツリー構築アリゴリズム
パーサーの作成時に Document オブジェクトが作成されます。ツリー構築段階で、ルートに Document を持つ DOM ツリーが変更され、要素が追加されていきます。
上の例でもう一度見ていく
- ツリー構築段階への入力はトークン化段階からの一連のトークンです。最初のモードは「initial」モードです。
- html トークンを受け取ると「before html」モードに移り、そのモードでトークンの再処理が行われます。
- モードは「before head」に変わります。次に body トークンを受け取ります。
- トークン名は「head」ではありませんが、暗黙的に HTMLHeadElement が作成され、ツリーに追加されます。
- ここで「in head」モードに移り、次に「after head」モードに移ります。
- body トークンが再処理され、HTMLBodyElement が作成および挿入されると、モードは「in body」に移ります。
- body end トークンを受け取ると、「after body」モードに移ります。html end トークンを受け取ると、「after after body」モードに移ります。
- end of file トークンを受け取ると解析が終了します。
CSS の解析
HTML とは異なり、CSS は文脈自由文法なので、概要で述べた種類のパーサーを使って解析することができます。
CSS 仕様(英語)では、CSS の語彙文法と構文文法を定義しています。
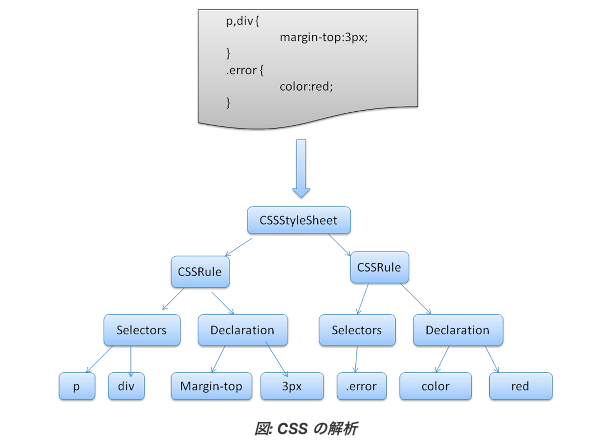
以下のような例の場合は
div.error , a.error {
color:red;
font-weight:bold;
}
ルールセットはこのようになっている
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Webkit の CSS パーサー
Webkit では Flex と Bison パーサー ジェネレータを使用して、CSS 文法ファイルからパーサーを自動的に作成します。
スクリプトとスタイル シートの処理順序
スクリプトの場合
ウェブのモデルは同期的です。制作者は、パーサーが <script> タグに達するとすぐにスクリプトが解析、実行されると想定しています。ドキュメントの解析はスクリプトが実行されるまで中断されます。
投機的な解析
Webkit と Firefox のいずれもこの最適化を行っています。スクリプトの実行中に別のスレッドでドキュメントの残りを解析し、ネットワークから読み込む必要のある他のリソースを探して、読み込みます。このようにリソースの読み込みを並列接続上で行うため、全体的な速度が向上します。
スタイル シート
一方、スタイル シートは異なるモデルです。理論的には、スタイル シートは DOM ツリーを変更しないため、スタイル シートの読み込みを待ってドキュメントの解析を中断する理由はないように思われます。しかし、ドキュメントの解析段階でスクリプトがスタイル情報を要求するという問題があります。スタイルの読み込みと解析がまだ済んでいない場合、スクリプトは誤った回答を受け取ることになり、さまざまな問題を引き起こす可能性があります。これは特殊なケースのように見えますが、実際にはよく起きています。
レンダー ツリーの構築
DOM ツリーを構築する間に、ブラウザは「レンダー ツリー」という別のツリーも構築します。このツリーは、視覚的な要素を表示順に並べたツリーであり、ドキュメントの視覚的な表現です。レンダー ツリーの目的は、コンテンツを正しい順序で描画できるようにすることです。
Webkit のレンダラーの基本クラスである RenderObject クラスは次のように定義されています。
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
ボックスの種類は、そのノードに関連する「display」スタイル属性に影響されます
次の Webkit のコードは、DOM ノードに対してどの種類のレンダラーを作成するかを display 属性に従って決定するコードです。
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
レンダー ツリーと DOM ツリーの関係
レンダラーは DOM 要素に対応していますが、その関係は 1 対 1 ではありません。視覚的でない DOM 要素はレンダー ツリーに挿入されません。その例として「head」要素が挙げられます。display 属性に「none」が指定されている要素もツリーには含まれません(visibility 属性に「hidden」が指定された要素はツリーに含まれます)。
ツリー構築のフロー
Webkit では、スタイルを解決してレンダラーを作成する処理を「関連付け(attachment)」といいます。各 DOM ノードには「attach」メソッドがあります。関連付けは同期的に行われ、DOM ツリーにノードが挿入されると、新しいノードの「attach」メソッドが呼び出されます。
html タグと body タグを処理すると、レンダー ツリーのルートが構築されます。ルートのレンダー オブジェクトは CSS 仕様で「包含ブロック」と呼ばれるものに相当します(他のすべてのブロックを含む最上位のブロックです)。その寸法はビューポート(ブラウザ ウィンドウの表示領域の寸法)です。
レンダー ツリーを構築するには、各レンダー オブジェクトの視覚的プロパティを計算する必要があります。この処理は各要素のスタイル プロパティを計算することで行います。
スタイルの計算にはいくつかの問題点があります。
- スタイル データは多数のスタイル プロパティを含む非常に大きな構造体なので、メモリの問題が起きる可能性があります。
- 最適化されていない場合、要素ごとにマッチング ルールを探索すると、パフォーマンスの問題が起きる可能性があります。
- 適用するルールには、ルールの階層を定義した非常に複雑なカスケード ルールもあります。
Webkit のノードはスタイル オブジェクト(RenderStyle)を参照しています。条件によっては、複数のノードでこのオブジェクトを共有することができます。
ノードが「兄弟」か「いとこ」の関係にあり、要素が次の条件に該当する場合です。 - マウスの状態が同じ(たとえば、一方が「:hover」で、もう一方が「:hover」でない場合は該当しない)。
- いずれの要素にも id がない。
- タグ名が一致する。
- クラス属性が一致する。
- マッピングされた属性のセットが同一である。
- リンクの状態が一致する。
- フォーカスの状態が一致する。
- いずれの要素も属性セレクタの影響を受けていない。「影響を受ける」とは、セレクタ内のどこかに属性セレクタを使用しているセレクタの照合がある場合です。
- 要素にインラインのスタイル属性がない。
- 「兄弟」セレクタがまったく使用されていない。WebCore では、兄弟セレクタに遭遇した場合は単にグローバル スイッチを送出し、表示時のドキュメント全体のスタイル共有を無効にします。これには + セレクタ、「:first-child」や「:last-child」などのセレクタがあります。
##### 構造体への分割
スタイル コンテキストは構造体(struct)に分かれています。この構造体には、ボーダーや色など、特定の種類のスタイル情報が格納されます。構造体のすべてのプロパティは「継承型」か「非継承型」です。継承型のプロパティとは、要素で定義されていない場合はその親から継承されるプロパティです。非継承型のプロパティ(「リセット」プロパティともいいます)では、定義されていない場合はデフォルト値が使用されます。
構造体全体(計算済みの最終値を含む)をツリーにキャッシュすることができます。下位のノードで構造体の定義に対応できない場合は、上位のノードにキャッシュされている構造体を使用できます。
ルール ツリーを使用したスタイル コンテキストの計算
- 特定の要素のスタイル コンテキストを計算する場合は、まず、ルール ツリー内のパスを計算するか、既存のパスを使用します。
- 次に、パスのルールを適用して、新しいスタイル コンテキストの構造体を埋めていきます。
- パスの下位ノード(優先度が一番高いノード。通常は最も限定的なセレクタ)から始めて、構造体が埋まるまでツリーをさかのぼります。そのルール ノードに構造体の定義がない場合は、構造体を完全に定義し、直接指しているノードが見つかるまでツリーをさかのぼります。
ここが最適化されている点で、構造体全体が共有されることになります。これにより最終値の計算が省略され、メモリも節約できます。
構造体の定義が見つからなかった場合、構造体が「継承型」の場合は、コンテキスト ツリー内の親の構造体を指すことになります。この場合も構造体は共有されます。「リセット型」の構造体の場合は、デフォルト値が使用されます。
(例) ```html
this is a big error this is also a very big error error
div {margin:5px;color:black} .err {color:red} .big {margin-top:3px} div span {margin-bottom:4px} #div1 {color:blue} #div2 {color:green}
color 構造体には 1 つのメンバー(color)しかありません。margin 構造体には 4 つの辺があります。
生成されるルール ツリーは次のとおりです
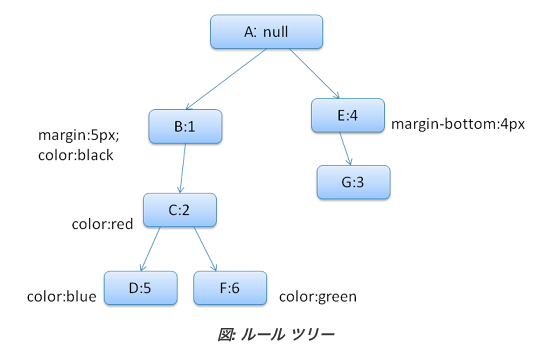
ルール ツリーのない Webkit では、一致した宣言が 4 回走査されます。まず、重要でないが優先度の高いプロパティ(他のプロパティがそのプロパティに依存しているため、最初に適用すべきプロパティ。display など)が適用され、次に優先度の高い重要なルール、通常の優先度で重要でないルール、通常の優先度で重要なルールの順に適用されます。つまり、複数回登場するプロパティは、正しいカスケード順序に従って最終的に解決されます。
#### 一致しやすくするためのルールの操作
スタイル ルールにはいくつかのソースがあります。
CSS ルール。外部のスタイル シートまたは style 要素。
```css
p {color:blue}
インラインの style 属性。
<p style="color:blue" />
HTML の視覚的属性(関連するスタイル ルールにマッピングされる)
<p bgcolor="blue" />
後者の 2 つは、要素に簡単に一致させることができます。要素自身にスタイル属性があり、その要素をキーとして使って HTML 属性をマッピングできるためです。
スタイル シートのカスケード順序
スタイル プロパティの宣言が複数のスタイル シートにあったり、1 つのスタイル シートで何度も出てきたりする場合があります。その場合はルールを適用する順序が非常に重要になります。これを「カスケード順序」といいます
(低から高の順)
- ブラウザの宣言
- ユーザーの通常の宣言
- 制作者の通常の宣言
- 制作者の重要な宣言
- ユーザーの重要な宣言
セレクタの特異性(specificity)は CSS2 仕様(英語)で次のように定義されています。
- 宣言がセレクタ付きのルールではなく「style」属性にある場合は 1 とカウントし、そうでない場合は 0 とカウントする(= a)
- セレクタ内の ID 属性の数をカウントする(= b)
- セレクタ内の他の属性と擬似クラスの数をカウントする(= c)
- セレクタ内の要素名と擬似要素の数をカウントする(= d)
(大きな基数の数体系で)4 つの数 a-b-c-d を連結すると、特異性が算出されます。
レイアウト
レンダラーを作成してツリーに追加したとき、レンダラーには位置やサイズがありません。これらの値を計算することを「レイアウト」または「リフロー」といいます。
HTML ではフローに基づいたレイアウト モデルを使用しています。つまり、ほとんどの時間、1 つのパス上で配置の計算が可能です。通常、フロー内で後の方の要素が最初の方の要素の配置に影響を与えることはないため、ドキュメントの左から右へ、上から下へとレイアウトを進めることができます。
レイアウトは再帰的な処理です。HTML ドキュメントの <html> 要素に対応するルートのレンダラーから始まります。レイアウトはフレーム階層の一部またはすべてを再帰的に進みながら、各レンダラーで必要な幾何学的情報を計算していきます。
ダーティ ビット システム
小さな変更があるたびに完全なレイアウト処理を行わなくても済むように、ブラウザでは「ダーティ ビット」システムを使用しています。変更または追加されたレンダラーは自身とその子を「ダーティ」としてマークし、レイアウトが必要なことを表します
グローバル レイアウトとインクリメンタル レイアウト
レンダー ツリー全体のレイアウトを開始することができます。これを「グローバル」レイアウトといいます。グローバル レイアウトは次のような場合に行われます。
- すべてのレンダラーに影響するグローバルなスタイルの変更(フォント サイズの変更など)があった場合。
- 画面がサイズ変更された場合。
レイアウト処理
幅の計算
次のような div の幅は、
<div style="width:30%"/>
Webkit によって次のように計算されます(RenderBox クラスの calcWidth メソッド)。
コンテナの幅は、コンテナの availableWidth と 0 のうち大きい方の値です。この場合の availableWidth は次のように計算される contentWidth です。
clientWidth() - paddingLeft() - paddingRight()
描画の順序
- 背景色
- 背景画像
- ボーダー
- 子
- アウトライン
参考資料
Browser ページの生成: ブラウザーの動作の仕組み
ウェブの性能における 2 つの主要な課題は、レイテンシーに関する諸問題と、多くの場合ブラウザーはシングルスレッドであるという事実に関する諸問題を理解することです。
レイテンシーは、速い読み込みを実現するために克服しなければいけない一番の脅威です。読み込みを速くしようとする開発者のゴールは、リクエストされた情報をできる限り速く送信すること、または少なくともとても速いように見せることです。ネットワークのレイテンシーは、バイト情報をコンピューターまで送信するのにかかる時間のことです。ウェブの性能は、ページの読み込みを出来る限り速くするよう私たちが何をするかにかかっています。
多くの場合、ブラウザーはシングルスレッドだと考えられます。スムーズな操作を実現しようとする開発者のゴールは、滑らかなスクロール、タッチ操作への反応など、期待通りのサイトの操作を実現することです。メインスレッドが全ての処理を時間内に完了し、その上でユーザーの操作を常にハンドリングできるよう保証するために、描画時間が鍵となります。
ナビゲーション
ナビゲーションはウェブページを読み込むための最初の一歩です。ユーザーが URL をアドレスバーに入力したり、リンクをクリックしたり、またはフォームを送信したり、ページをリクエストするたびごとにナビゲーションが発生します。
ウェブの性能における目標の 1 つは、ナビゲーションが完了するまでの時間を最小限にすることです。
DNS ルックアップ
これまでに一度もそのサイトを訪れたことがなかった場合、DNS ルックアップが必要になります。
ブラウザーが DNS ルックアップをリクエストし、そのリクエストは最終的にネームサーバーによって処理され、ネームサーバーが IP アドレスを返します。この最初のリクエストの後、多くの場合その IP アドレスはしばらくの間キャッシュされ、ネームサーバーへ再接続する代わりにキャッシュから IP アドレスを取得することによって、後続するリクエストの速度を向上します。
DNS ルックアップは、一般的に、1 回のページ読み込みの中でホスト名ごとに 1 回だけ必要になります。しかし、DNS ルックアップは要求されたページが参照するユニークなホストネームそれぞれに対して実行が必要です。必要なフォントや画像、スクリプト、広告、メトリクスのそれぞれが異なるホスト名を持っている場合は、それぞれに対して DNS ルックアップが必要です。
TCP ハンドシェイク
IP アドレスが判明すると、ブラウザーは TCP 3 ウェイハンドシェイクを通じてサーバーとのコネクションを設定します。
TLS ネゴシエーション
HTTPS によって確立される安全なコネクションでは、もう 1 つのハンドシェイクが必要です。このハンドシェイク、より正確に言うと TLS ネゴシエーションは、通信の暗号化に使用する暗号の種類を決定し、サーバーを認証し、実際のデータ送信が始まる前に安全な通信の準備を整えます。
レスポンス
TCP スロースタート / 14kB ルール 最初の応答パケットは 14kB になります。これは、TCP スロースタート (en-US)の一部で、ネットワークコネクションの速度を制御するアルゴリズムの影響です。スロースタートは、ネットワークの最大の帯域幅が確定するまで徐々に送信するデータ量が増やします。
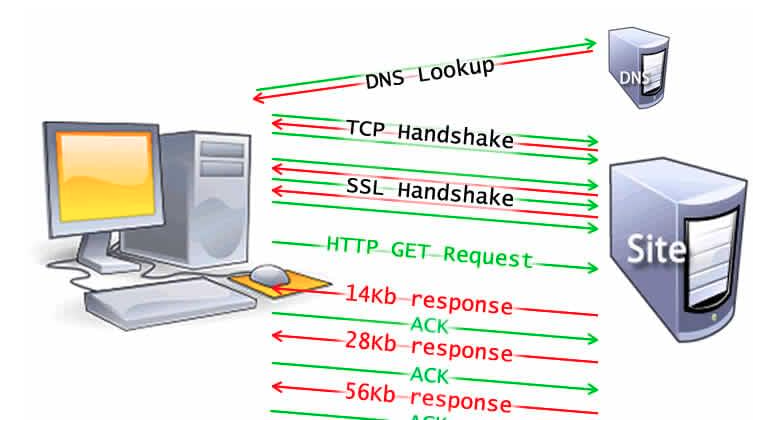
パース処理
データの最初のかたまりを受け取ると、ブラウザーは受信した情報のパース処理を始めることができます。パース処理は、ネットワークから受信したデータを DOM と CSSOM に変換するステップです。DOM と CSSOM は、レンダラーがページを画面へ描画するために利用されます。
DOM ツリーの構築
最初のステップは HTML のマークアップを処理し、DOM ツリーを構築することです。
ドキュメントが正しく構成されていればパース処理は単純で、速度も速くなります。パーサーはトークン化された入力情報をドキュメントツリーを構成するドキュメントに変換します。
プリロードスキャナー
ブラウザーが DOM ツリーを構築する間はそのプロセスがメインスレッドを占有します。その間にプリロードスキャナーが処理可能なコンテンツをパースし、CSS や JavaScript、ウェブフォントのような優先度の高いリソースのリクエストを行います。プリロードスキャナーのおかげで、リクエストするべき外部リソースへの参照をパーサーが見つけるのを待たなくて良くなります。
<link rel="stylesheet" src="styles.css"/>
<script src="myscript.js" async></script>
<img src="myimage.jpg" alt="image description"/>
<script src="anotherscript.js" async></script>
この例では、メインスレッドが HTML と CSS をパースしている間に、プリロードスキャナーがスクリプトと画像を探索し、それらのダウンロードを開始します。もし JavaScript の実行順序が重要でないなら、スクリプトがプロセスをブロックしないように async 属性または defer 属性を追加しましょう。
CSS の取得は HTML のパース処理あるいはダウンロードをブロックしません。しかし JavaScript の実行をブロックします。その理由は、しばしば JavaScript が CSS プロパティの要素への影響を問い合わせるために使われるからです。
CSSOM の構築
クリティカルレンダリングパスの 2 つめのステップは CSS を処理して CSSOM ツリーを構築することです。CSS のオブジェクトモデルは DOM によく似ています。DOM と CSSOM はどちらもツリー構造です。この 2 つは独立したデータ構造を持ちます。ブラウザーは、CSS のルールをブラウザーが理解できるスタイルのマップに変換します。
CSSOM ツリーはユーザーエージェントのスタイルシートから取得したスタイルを含みます。ブラウザーは、ノードに対して適用される最も一般的なルールからスタートして、より特定されたルールを再帰的に適用し、最終的なスタイルを計算します。
JavaScript のコンパイル
CSS がパースされ、CSSOM が生成される間、JavaScript ファイルを含む他のアセットが(プリロードスキャナーによって)ダウンロードされます。JavaScript は、インタープリターに処理され、コンパイル、パース処理を経て実行されます。スクリプトはパース処理によって抽象構文木に変換されます。いくつかのブラウザーエンジンは、抽象構文木をインタープリターへ引き渡し、メインスレッドで実行されるバイトコードを出力します。これが JavaScript のコンパイル処理に当たります。
レンダリング
レンダリングのステップは、スタイル、レイアウト、描画、そして合成で構成されます。パースのステップで作成された CSSOM と DOM のツリーはレンダーツリーの形式へと組み合わされ、すべてのビジュアル要素のレイアウトを計算するために使用されてスクリーンに描画されます。いくつかのケースでは、CPU の代わりに GPU を使用してスクリーンの一部を描画し、メインスレッドを解放してパフォーマンスを改善するために、コンテンツ自身をレイヤーに昇格し、合成を行います。
スタイル
クリティカルレンダリングパスの 3 番目のステップは DOM と CSSOM をレンダーツリーの形式へと組み合わせることです。計算されたスタイルのツリー、あるいはレンダーツリー、の構築は DOM ツリーのルートからスタートし、目に見える (Visible) ノードをトラバースします。
ユーザーエージェントのスタイルシートにある <head> のような表示されることないタグとその子要素、script { display: none; } のように display: none を指定されたすべてのノード、はレンダリングの結果に影響しないためレンダーツリーには含まれません。visibility: hidden が適用されたノードは、スペースを確保するためレンダーツリーに含まれます。
レイアウト
クリティカルレンダリングパスの 4 番目のステップは各ノードの平面状の位置を計算するためにレイアウト処理を実行することです。レイアウトはレンダーツリーに含まれるすべてのノードの幅と高さ、位置を決める処理です。
レンダーツリーが構築されるとすぐにレイアウトが始まります。レンダーツリーは計算されたスタイルを踏まえてどのノードが表示されるか (非表示であっても) 特定しますが、寸法や位置は特定しません。
ノードのサイズとポジションが決められる最初のタイミングをレイアウトと呼びます。続いて発生するノードのサイズと位置の再計算を再フロー呼びます。私たちの例では、画像が返される前に最初のレイアウトが発生すると考えられます。画像のサイズを宣言していなかったため、画像のサイズがわかるとすぐに再フローが発生します。
描画
クリティカルレンダリングパスの最後のステップは個別のノードをスクリーンに描画することです。最初に発生する描画を first meaningful paint と呼びます。
スムーズなスクロールとアニメーションを実現するために、スタイルの計算や再フロー、描画などメインスレッドを占有するすべての処理は、16.67ms 未満で完了する必要があります。
2回目以降の描画を最初の描画より高速にするため、スクリーンへの描画は一般的に複数のレイヤーに分解されます。この場合に合成が必要になります。
描画は描画ツリー内の要素をレイヤーに分解します。コンテンツを GPU (CPU 上のメインスレッドの代わりになる) 上のレイヤーに昇格させることで、描画と再描画のパフォーマンスを向上します。<video> や<canvas>など、レイヤーを生成する特定のプロパティと要素があります。
合成
ドキュメントのセクションが異なるレイヤーに描画されて重なり合う場合、コンテンツをスクリーン上に正しい順番で描画するために合成が必要になります。
ページがアセットの読み込みを続ける間も再フローは発生します (後ほど出てくる図を見てください)。再フローは再描画と再合成を引き起こします。
画像がサーバーから取得されたとき、レンダリングプロセスはレイアウトステップまで戻り、そこから再開します。